

 上一版
上一版

【成果发布】
编者按
为更好地服务中国特色新型智库建设、弥补我国智库数据管理和在线评价工具的空白,由南京大学中国智库研究与评价中心、光明日报智库研究与发布中心联合研发的“中国智库索引”(简称CTTI),于9月28日正式上线。为使广大读者和用户全面、深入了解CTTI有关情况,兹发布此研制报告。
1、研发背景
党的十八大和十八届三中全会要求加强中国特色新型智库建设,建立健全决策咨询制度,启动了智库建设的国家战略。此后,我国新型智库的发展迎来了一个黄金时期。
然而,直到目前我国还没有建立起一套完整的智库情况统计分析方法。科技部曾在2011年组织开展过一次“全国软科学研究机构统计调查报告”,统计结果是中国共有各类型软科学研究机构2408家。谢寿光、蔡继辉主编的《中国智库名录》登记了1137家智库(不包含港澳台)。2016年1月上海社会科学院智库研究中心发布的《2015年中国智库报告》,认为中国的活跃智库有300余家。可见,对于中国到底有多少家智库,意见差别很大。缺乏智库统计指标体系是导致我国没有完整系统的智库统计数据的主要原因。这不仅不利于各级政府对辖区内建设中国特色新型智库发展态势的掌握,也影响各级政府在科学决策过程中对智库资源的利用,而且使我国的智库评估评价等智库管理和研究缺乏必要的数据支撑。
为了记录、保存、集成智库信息,美国哈佛大学肯尼迪政府学院图书馆提供了专门的“智库搜索”检索工具,对智库的检索,准确率几乎提升了一个数量级。Lynn John Hellebust和Kristen Page Hellebust编辑出版的《智库名录:独立非营利政策研究机构指南》是美国智库研究的权威工具书。但是,肯尼迪政府学院图书馆的智库搜索没有自己独立的索引库,是谷歌为它定制的垂直搜索引擎。而《智库名录》只记录智库基本信息,包含了13个字段。
为解决全面描述、全面收集智库数据,提供数据整理、数据检索、数据分析、数据应用的功能,南京大学中国智库研究与评价中心联合光明日报智库研究与发布中心开展了“中国智库索引”(简称CTTI)的研究开发工作。2015年6月成立了以李刚教授为主持人的课题组,系统研发经历三个阶段。2015年6月至10月属于第一阶段,完成了系统需求分析、字段设计,确定了系统设计的基本思想,明确了系统架构设计。在10月18日由光明日报理论部和南京大学共同主办的“新型智库机构评估与治理创新专题研讨会”上发布了CTTI的中期研究成果,被业内视为2015年智库界十大事件之一。2015年11月至2016年6月属于系统开发的第二阶段,完成了CTTI的系统开发。2016年7月至9月属于第三阶段,这一阶段完成了系统环境部署,上线内测,以及委托第三方测试系统安全性等工作。9月28日上线发布,可以开放给被收录的来源智库录入数据。
2、目标与设计理念
CTTI的基本目标和需求有三个。第一,对新型智库的各要素进行准确“画像”,力求全面准确描述和反映智库的基础信息、人员、成果、活动、影响力等诸方面的情况。第二,以完备的字段作为支撑,以多角度查询的方式全方位展示查询结果,实现对智库机构从内部架构到外部活动、从人员组成到成果发布的立体式展示。用户(政府、企业事业单位、社会团体等)有大量的政策研究、咨询需求,但是它们未必知道谁是最恰当的解决方案提供者,而智库也经常处于任务不足,不知道客户在哪里的情形。CTTI设计目标之一就是解决这种信息不对称情况。第三,为新型智库评估评价提供针对性的基础数据。
根据基本目标,课题组确定了相应的设计理念和设计要求。
第一,智库“画像”和专家“画像”必须全面准确,要从多个维度对智库和专家各要素进行描述,字段设计宁可冗余,也不能出现有数据而无对应的字段的情况。
第二,把这一在线大型数据库设计成为一个智库的“垂直搜索引擎”(专业搜索),实现对智库各种信息的智能分析,快速准确检索到目标信息。比如某机构发布需求需要寻求计划生育方面的研究专家,那么我们就可以锁定研究领域为计划生育的专家,根据对他们年度成果、活动的评价,进行排名选择。
第三,对接智库评价的新理念。CTTI不是单纯的智库数据管理系统,还有智库评价,这是后期数据应用的主要目的之一。对于智库评价,目前主要有两种方式:一是影响力评价,比如上海社科院的评价体系;二是资源—绩效评价,比如麦甘的《全球智库报告》,中国社科院的AMI全球智库综合评价模型也属于资源—绩效评价。它们的共同点是都属于“分值评价模型”,根据分值(这个分值可能来自专家问卷,也可能来自一些定量数据)的大小进行排名。大部分排行榜都只取少数几个因素来排名。我们在设计CTTI的时候,考虑到构建的评价模型必须是一种多因子评价模型。CTTI评价因子不是几个,而是几十个甚至上百个。另外,CTTI评价模型是一种学习模型,具有智能分析评价的特征,不是简单地算一个分值,给出排名,而是具备自主根据评价对象的不同,自动进行权重赋值。CTTI评价模型也不仅是一个模型、一个算法,而是准备开发出一组模型、一组算法,根据不同的评价目的调用不同的算法,这样可以使评价更具针对性和个性化。为了实现评价上的突破,CTTI的设计理念也将不断追求更新与突破。
第四,确保数据安全,争取达到准金融数据安全级别。CTTI由底层数据库和顶层应用系统两部分组成。为达到CTTI的预期目标,在进行框架安排和功能设计时,采用底层数据库字段做加法,顶层功能设计做减法,后台管理系统做加法,前台应用系统做减法的设计思想。一方面使得CTTI的数据字段和数据库设计较为完备,另一方面使其顶层功能和前台应用可面向未来需要做灵活扩充。
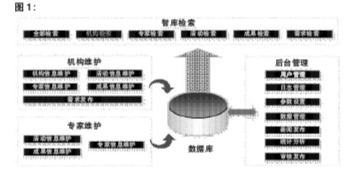
从用户角度区分,CTTI的应用系统如图1所示,分别是检索模块、机构应用模块、专家应用模块以及后台管理模块。
3、数据库设计
CTTI的数据库设计面向智库信息检索和管理的需求,力求全面收集智库机构、专家、产品和活动的所有信息。CTTI的数据库部分的设计目标是,将现在和未来所有可能汇集到的智库数据都能够分门别类地存储进数据库。为了达到这一目标,CTTI数据库的设计采用“加法”思想,即前期通过开展智库普查以多次手工收集数据的方式实现对我国现有所有类型的智库、专家、产品和活动的全覆盖。通过充分调研,将CTTI的数据库划分为机构数据库、专家数据库、机构产品数据库和机构活动数据库四个数据库子集。
(1)机构数据库
机构数据库子集面向智库机构索引需求,包含机构自然概况、社会联系、机构影响力等总共50个大类305个字段。
(2)专家数据库
专家数据库子集面向智库专家索引需求,包含专家自然概况、任职经历、身份、成果、荣誉、影响力等总共36个大类238个字段。其中影响力数据包括官方网站、搜索引擎显示度、微博等13类社会影响力数据,内参、报告和批示等3类政策影响力数据,论文、期刊、项目等5类学术影响力数据。
(3)产品数据库
产品数据库子集面向智库产品索引需求,将智库产品进一步细分为报告、电子出版物、论文、内参、期刊、其他出版物、时事通讯、视频资料、图书、项目等10个大类共计234个字段。
(4)活动数据库
活动数据库子集面向智库活动索引需求,将智库的活动细分为会议、培训、调研考察以及接待来访四大类,共计94个字段。
为确保数据规范性,CTTI采用数据字典的方式,对学科门类、地区代码、民族代码、会议级别等81项内容进行了规范化汇总,由系统管理员维护。需求发布和查询是CTTI的一个应用功能,该功能面向机构用户,以满足人员招聘和课题招募的需求。该功能由一个单独的数据库作为支撑,独立于上述4个数据库之外。除此之外,CTTI作为一个完整的检索系统还包含代码对照表、关系映射表等数据库建模所必需的辅助文件,在此不做赘述。
4、任务流程设计
以强大的数据库为支撑,面向未来的增量需求,CTTI具备了完成多种任务的可能。就现阶段的需求而言,CTTI系统内部实现了三个任务流程:数据处理流程、检索流程和后台管理流程。下面将展开详细描述:
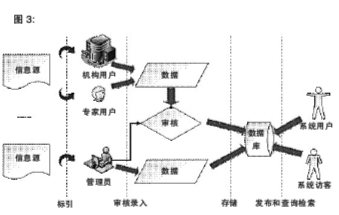
(1)数据处理流程
该流程主要完成的任务包括数据的录入、修改、审核、发布和维护。其中“数据”既包括前文所述的机构、专家、产品和活动数据,也包括新闻、需求信息等周边数据。数据来自手工收集的网络或纸质信息源。数据处理流程如图2所示。
在数据处理流程中,机构用户和专家用户可通过不同的入口登录系统,录入对应字段的数据。这些数据经系统管理员审核后发布或开放检索。系统管理员拥有审核权和数据管理的最高权限。对于审核后的数据,所有系统用户和访客都可以直接检索查询。
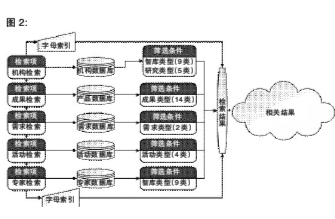
(2)检索流程
检索流程包括机构检索、专家检索、产品检索、活动检索、需求检索以及综合检索等六类任务。CTTI支持模糊查询和多条件查询。多条件查询只需以空格分隔条件即可,与常见搜索引擎使用方法一样。检索流程如图3所示。其中,综合检索是前五类检索的“或”操作。对于这五类检索任务,CTTI均提供对检索结果的二次筛选功能。筛选可选项如图3所示。每项筛选项下设若干个条件,可通过勾选完成筛选。对于机构和专家的检索,CTTI提供按字母索引,以便于快速查找。CTTI最终检索结果包括结果列表和相关结果两部分。结果列表是指符合检索条件的所有条目的列表。结果条目按照命中权重即检索字段匹配率从高到低排序。
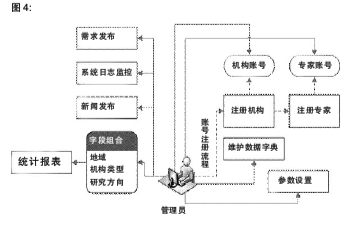
(3)后台管理流程
后台管理流程只对系统管理员开放,包括用户注册和身份管理、日志管理、参数设置、新闻发布、统计分析、数据管理和审核等,如图4所示,兹不赘述。
5、自主创新
CTTI不是对西方某个成熟产品的模仿,它的设计理念、功能布局、数据采集机制、评价机制等都是自主提出的。体现在以下几个方面:
第一,CTTI建立了共建共享的数据采集机制,重视数据的客观性和准确性。CTTI的数据采集有三种形式:依靠来源智库和专家自主填报、南京大学中国智库研究与评价中心手工收集、网上数据自动抓取。目前第一种方式是主流,数据由智库机构管理员或者专家本人录入,提交给CTTI后台审核,每一条数据都经过后台审核准确无误才提交到数据库。这种数据采集机制表面上人工投入巨大,实际上由于采用了时下最流行的“众包”(众筹)模式,数据共建共享,数据采集成本分摊到每一个参与者,反而是比较低廉的。由于是人工模式,数据的准确性和客观性大大增强。为减少人为干扰影响力数据的情况,CTTI每个智库每个专家的影响力数值除后台管理员填报的少数字段外,都是根据填报的数据自动计算出影响力数值。
第二,CTTI的用户界面设计和用户体验达到了同类产品的前沿水平。比如,CTTI允许几百上千人同时录入数据。由于现代科研中合作研究是一种常态,那么一定会出现同一篇文献不同专家不同智库先后录入各自名下这种场景。那么在CTTI中录入数据时,只要出现关联数据,系统就会自动拉取原来存在的数据,让最近的录入者修改补充。这样不仅杜绝了雷同数据,而且节省了数据录入量。再比如CTTI在数据录入界面设计了大量醒目的按钮,用户可以随时保存、修改、调用数据,杜绝了因误操作丢失数据的情况。另外,CTTI几乎为每个字段都提供了数据录入提示语,提示语不仅解释了字段的含义,而且给出了示例。这样数据录入人员无需查阅系统说明书就可以知道如何准确地录入数据。
第三,CTTI系统和数据安全性达到了准金融数据安全级别。在部署方案上,CTTI将应用服务器与数据服务器分开部署,采用内外网隔离的方案,公网用户只能访问应用服务器,无法直接访问到数据服务器,保证了数据的安全性;在通讯协议方面,CTTI使用https的SSL加密协议,保证所有请求数据在传输的过程中都是加密的,防止攻击者通过拦截、篡改请求内容非法访问系统;由于CTTI收录的数据众多,为了防止系统数据被轻易窃取,CTTI在反扒网方面也做了应对设计,采用了B/S架构并以科学的权限设置和角色分配保障信息的可用性和可控性,一般访客访问系统只能查询到最基本的数据,无法看到系统的全貌,后续我们也将对客户端IP访问频率增加限制,避免出现非人为操作的破坏性攻击。
第四,CTTI创新了用户分层服务模式。CTTI的用户有需要利用智库的党和政府的政策研究机构,有负责智库注册、指导的民政局、宣传部等部门,有智库管理员和专家等机构内部用户,有大学、科研院所等学术单位,有报刊、网站等媒体,有各种企业等营利部门,还有一般的公众。CTTI设计了分层服务方案,根据不同层次的用户访问到的数据层次和类型不同,给予针对性的服务。比如,各种统计图标、统计工具在设计时就充分考虑了行政管理部门的需要。在数据的呈现与导出方面,充分考虑了智库的需要,智库和专家可以方便地在CTTI中进行数据管理与导出。又比如为了方便系统管理员的风险应急管理,CTTI提供了瞬间关闭某一个智库全部数据而不影响其他智库数据的功能。这样即使个别智库数据出现敏感问题,也不需要关闭整个系统。
第五,CTTI在一定意义上建立了中国特色新型智库的统计指标体系和元数据标准。全部871个字段实现了对智库基本信息、专家信息、成果信息、活动信息的各种属性的全面覆盖,给出了立体的智库各要素画像。这些数据字段可以成为今后其他智库系统开发的元数据。
可以预见,CTTI将对我国哲学社会科学研究领域产生重要影响,对我国哲学社会科学界开展以问题为导向的研究起到强有力的辅助和促进作用。CTTI的成功上线填补了我国智库数据管理和在线评价工具的空白,为我国智库评价工作提供了基础数据,理清了新型智库评价这项集机构评价、成果评价、人员评价以及活动评价的复杂工作的头绪,并引导这项工作趋于理性和客观。但是,目前CTTI推出的毕竟是测试版,使用过程中还会出现不少问题,甚至错误。我们欢迎智库界和用户对CTTI提出宝贵意见,以便在二期开发中采纳改进。
(课题组成员:唐军、梅开祥、刘利、马密坤、薛蕾、陈媛媛、黄松菲、孔放、黄丽雯、邹静雅、董成颖、李璐璐、高琪娜、庆海涛、丁怡、甘琳、王琪、赵凯、王利宝、姜彬、汤明松、潘海霞、毕俊)
 缩小
缩小 全文复制
全文复制